MiniMax M2.5 : Performances SOTA à 1/20e du prix de Claude Opus 4.6

Contexte : L'Efficacité MoE Face aux Géants
Les LLM occidentaux comme Claude Opus 4.6 (Anthropic) ou GPT-5 excellent en précision mais souffrent d'inférences coûteuses : latence élevée et besoins GPU massifs (souvent 8x H100+). M2.5 adopte un MoE sparse : seuls 10B paramètres s'activent par token, réduisant la compute de 92% vs modèles denses comparables, tout en maintenant un Intelligence Index de 61 (top open-source). Open-sourcé sous MIT et compatible OpenAI API, il cible les devs et entreprises cherchant du SOTA accessible (4 H100 FP8 suffisent pour production).
MiniMax surfe sur la maturité chinoise en scaling laws optimisées, priorisant throughput (100 tokens/s) et concurrency pour agents IA, coding polyglotte et refactoring.
Mécanisme Technique de M2.5
M2.5 excelle via :
- Architecture MoE : 230B totaux, 10B actifs — routing expert dynamique minimise la latence sans perte qualité.
- Fenêtre Contexte : 204K input / 131K output tokens, avec function calling, structured output et reasoning mode natifs.
- Versions Optimisées : M2.5-highspeed (latence ultra-basse), Stable (haute concurrency) — idéal pour SaaS multi-tenant.
- Entraînement : RLHF sur tâches complexes (Excel modeling, multi-SWE-Bench multilingue), boostant token efficiency.
Prix : 0,30$/1M tokens input (1/20e de Claude Opus ~6$/1M), output à 1/10-1/20e, rendant viable le déploiement edge ou cloud low-cost.
Résultats sur Benchmarks
M2.5 domine les open models et approche les closed SOTA :
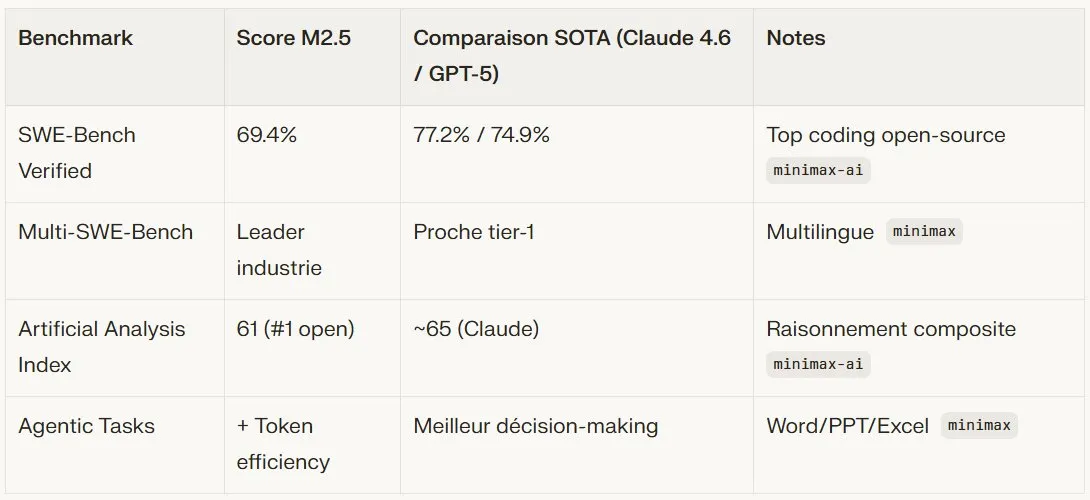
Sur LiveCodeBench et GPQA, M2.5 offre 100 TPS avec concurrency, vs latences prohibitifs des concurrents à volume.
Implications Professionnelles : Guerre des Coûts Chinoise
M2.5 confirme l'offensive chinoise en inférence low-cost : pour prestataires IT/SaaS (CRM, SIRH IA-augmentés), cela divise OPEX par 20 sur tâches coding/agentic, favorisant adoption massive en B2B Asie/Europe. Les gains MoE (logiciel-heavy) démocratisent SOTA, forçant OpenAI/Anthropic à baisser prix ou innover (ex: DMS Nvidia).
Perspectives 2026 : Weights Hugging Face imminents, intégration Kilo Code/VS Code gratuite accélèrent l'écosystème dev chinois. Une disruption où prix = nouveau moat compétitif, alignée sur souveraineté numérique et scaling rentable.