AMD démocratise l’agentique IA en local avec OpenClaw

OpenClaw sur hardware AMD : performances chiffrées
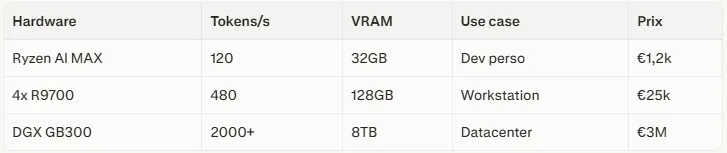
RyzenClaw (Ryzen AI MAX+) : APU unique traite 10k tokens entrée en 4,4s, output 120 t/s – idéal développeurs, stations perso.
RadeonClaw (4x Radeon AI PRO R9700) : 128GB VRAM pooled, modèles 128B params, workflows multi-agents (code, recherche, admin).
ROCm vs CUDA : AMD optimise OpenClaw via ROCm 7.x, setup WSL2 sous 1h, sans dépendance cloud (vs Bedrock/NemoClaw).
Configuration et cas d’usage
Installation express :
1. WSL2 + LM Studio (Ollama-compatible) 2. OpenClaw Docker via AMD template 3. Skills auto (email, WhatsApp, GitHub, calendrier) 4. Interface browser : "réserve vol + code review + email boss"
Use cases : code review auto, recherche agentique offline, admin système, prototyping R&D – tout local, zero-latence.
Analyse : AMD contre-attaque dans la guerre agentique
Timing stratégique post-GTC : NVIDIA NemoClaw (enterprise) vs AMD OpenClaw (edge/prosumer). ROCm mature (7.x) + Ryzen AI 300-series = alternative crédible CUDA lock-in.
Marché cible : early adopters (80% devs Linux), stations WS (CAD, simu), souveraineté (Europe post-MLPS2.0).
Critique : pari audacieux mais adoption freinée
Forces : prix 100x inférieur NVIDIA, offline=privacy, ROCm open. Limites : perf 4x inférieure DGX, ROCm < CUDA maturité, OpenClaw sécurité (Chine ban) → DSI frileux. Early adopters only vs entreprises.
Europe : RyzenClaw + OVH/Scaleway = souveraineté agentique sans AWS/Azure. PME tunisiennes (Mahdia) : Ryzen AI 300 + OpenClaw = R&D local à €1500.
Perspectives : l’ère des “Agent Computers”
AMD redéfinit le PC : “Agent Computer” = machine où IA résidente pilote apps/homme. Prochaines étapes :
- Q2 2026 : ROCm 8.0, OpenClaw Harbor (SailPoint-like)
- CES 2027 : laptops RyzenClaw consumer
- NVIDIA Datacenter, AMD Edge – guerre hardware agentique lancée.
TL;DR
AMD OpenClaw
- Edge agentic : OpenClaw sur RyzenClaw (APU) et RadeonClaw (4x R9700) exécute agents IA localement, 120 tokens/s, 128GB VRAM.
- Setup <1h : WSL2 + LM Studio pour LLMs offline (Llama, Mistral), WhatsApp/emails/calendrier pilotés depuis PC.
- Défi NVIDIA : AMD casse le lock-in CUDA, cible ingénieurs/early adopters vs NemoClaw entreprise.
Questions fréquentes
OpenClaw sur AMD est-il vraiment “plug and play” ?
Oui, <1h via WSL2 template AMD : LM Studio auto-configure LLMs, skills OpenClaw (email/WhatsApp) prêtes. ROCm drivers pré-installés Ryzen AI MAX+.
Performances vs NVIDIA/Cloud ?
RyzenClaw : 120 t/s (vs DGX 2000+), offline/privacy. RadeonClaw 4-GPU : 128B params local (vs Bedrock quotas). CUDA > ROCm, mais gap se resserre.
Sécurité post-ban Chine ?
Risques OpenClaw (one-click skills) → utiliser Harbor Pilot ou forks sécurisés. AMD cible pros/early adopters, pas prod bancaire.