Meta force les LLM à montrer leurs preuves avant de juger le code. La précision passe à 93 %.
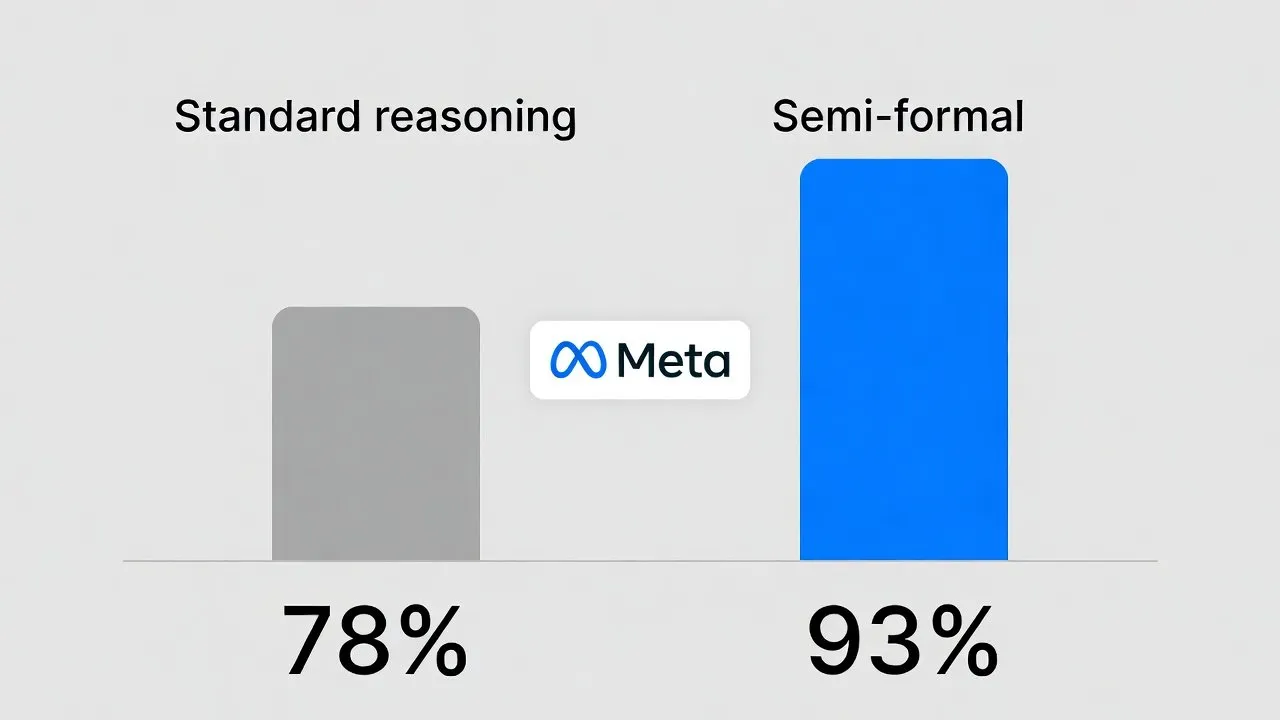
Shubham Ugare et Satish Chandra, chercheurs chez Meta, posent une question simple dans leur article publié sur arXiv : un agent LLM peut-il explorer un codebase et raisonner sur la sémantique du code sans l'exécuter ? La réponse, avec le raisonnement standard, est « à peu près, avec beaucoup d'hallucinations ». Avec leur technique de raisonnement semi-formel, la réponse devient « oui, avec une précision qui s'approche de celle nécessaire pour des applications en production ».
Le raisonnement semi-formel est un template de prompting structuré. L'agent reçoit un formulaire logique à remplir — un « certificat » — qui l'oblige à énoncer explicitement ses prémisses, tracer les chemins d'exécution concrets pour des tests spécifiques, et dériver une conclusion formelle uniquement à partir d'évidences vérifiables dans le code. Le template empêche l'agent de sauter des cas ou de faire des affirmations non étayées.
Pas d'entraînement de modèle. Pas de packaging spécial. Pas d'exécution de code. On paie plus de compute à l'inference pour obtenir une précision supérieure. Les templates sont disponibles en libre accès.
Le problème
L'industrie approche la vérification de code sans exécution par deux voies. La première : des évaluateurs LLM non structurés qui tentent de vérifier le code directement ou via des reward models entraînés. Le défaut principal : le raisonnement non structuré permet aux modèles de faire des affirmations confiantes sur le comportement du code sans justification explicite. Sans contraintes structurelles, rien ne garantit que l'agent raisonne rigoureusement plutôt que de deviner à partir de patterns superficiels — comme le nom des fonctions.
La seconde : la vérification formelle, qui traduit le code en langages mathématiques (Lean, Coq, Datalog) pour permettre la vérification automatique de preuves. Rigoureux, mais totalement impraticable pour des codebases enterprise arbitraires couvrant plusieurs frameworks et langages.
Le semi-formal reasoning occupe l'espace entre les deux : plus contraint que le chain-of-thought libre, plus flexible que la preuve mathématique.
Les résultats

Le chiffre de 93 % est obtenu sur des patchs réels générés par des agents, pas sur des exemples synthétiques. C'est le chiffre qui compte pour les applications industrielles. Les chercheurs le présentent comme approchant « la fiabilité nécessaire pour des signaux de reward RL sans exécution » — c'est-à-dire que la technique pourrait remplacer les sandbox d'exécution dans les pipelines d'entraînement par reinforcement learning, réduisant massivement les coûts de compute.
Résultat important mais discret : les gains avec Sonnet 4.5 sont sensiblement inférieurs, voire plats sur certaines tâches. Le template améliore le raisonnement des modèles qui en sont déjà capables. Il ne compense pas les limites des modèles plus petits. La technique est model-dépendante.
Comment ça marche
Le template de raisonnement semi-formel fonctionne comme un certificat logique obligatoire. Pour chaque tâche, l'agent doit remplir une structure prédéfinie qui exige : l'énoncé explicite des prémisses (ce que le code est censé faire, d'après les tests ou les spécifications), le traçage des chemins d'exécution concrets pour des inputs spécifiques, et la dérivation d'une conclusion formelle basée uniquement sur les évidences collectées.
Le mot clé est « concrets ». L'agent doit suivre les appels de fonctions et les flux de données pas à pas plutôt que de deviner leur comportement à partir de conventions de nommage. C'est cette collecte systématique d'évidences qui permet de traiter les edge cases — comme les noms de fonctions trompeurs — et d'éviter les affirmations non étayées.
Contrairement à la vérification formelle, le template n'encode pas la sémantique du langage de programmation. Il encode la méthode de raisonnement. C'est ce qui le rend généralisable à travers les langages et les frameworks. Les benchmarks couvrent Java (Defects4J), Python, et C++ (RubberDuckBench).
L'implication
Les chercheurs formulent une proposition qui devrait intéresser les équipes qui opèrent des outils d'analyse statique : le raisonnement agentique structuré pourrait offrir
« a flexible alternative to classical static analysis tools: rather than encoding analysis logic in specialized algorithms, we can prompt LLM agents with task-specific reasoning templates that generalize across languages and frameworks. »
C'est une affirmation forte. Les outils d'analyse statique (SonarQube, Semgrep, CodeQL) encodent leur logique dans des algorithmes spécialisés, maintenus par des équipes dédiées, spécifiques à chaque langage. Un template de prompting qui généralise à travers les langages réduirait la fragmentation des toolchains de sécurité. Mais les chercheurs notent eux-mêmes que la technique n'offre pas les « formal guarantees of traditional tools ». C'est un outil complémentaire, pas un remplacement — du moins à 93 %.
Pour les pipelines de reinforcement learning qui entraînent des agents de coding, l'impact est plus immédiat. Si la vérification de patchs atteint 93 % sans exécuter de code, les sandbox d'exécution — qui consomment beaucoup de compute et ne scalent pas bien — deviennent optionnelles pour une partie du pipeline. Le coût d'entraînement des agents de coding baisse. La vitesse d'itération augmente.
Les modes d'erreur résiduels documentés dans l'article : l'indirection manquée, l'incapacité à suivre des défauts répartis sur plusieurs fichiers, et le manque de connaissance algorithmique spécifique au domaine. Ce sont les cas que les 7 % d'erreur restants recouvrent. Ce sont aussi les cas que les développeurs seniors trouvent difficiles.
Post-training
Les chercheurs esquissent une direction future : fine-tuner les modèles pour internaliser la structure du template semi-formel. L'objectif : maintenir les gains de précision tout en éliminant le surcoût de prompting à l'inference. Si le modèle a appris à raisonner de manière semi-formelle nativement, le template externe devient inutile. C'est la transition naturelle d'une technique de prompting vers une capacité du modèle.
Pour l'instant, la technique a un coût : plus de tokens consommés à l'inference, un temps de traitement plus long par tâche. Le mode Deep Research de Slackbot, annoncé le même jour par Salesforce, prend environ quatre minutes par requête — un choix comparable de sacrifier la vitesse pour la profondeur. L'industrie converge vers l'idée que pour certaines tâches, la réponse instantanée est l'ennemi de la réponse correcte.
TL;DR
Meta publie un template de prompting qui force les LLM à prouver leurs affirmations avant de juger du code. La précision passe à 93 % sur des patchs réels. Sans exécution, sans entraînement, sans sandbox.
- Le « semi-formal reasoning » oblige l'agent à énoncer ses prémisses, tracer les chemins d'exécution concrets et dériver une conclusion formelle avant de valider un patch. Sur les patchs réels générés par agents, la précision atteint 93 % avec Opus 4.5 (vs 86 % en single-shot). Sur la compréhension de code (RubberDuckBench), 87 % (+9 points). Sur la localisation de fautes (Defects4J), +5 à +12 points en Top-5.
- La technique ne nécessite ni entraînement de modèle, ni exécution de code, ni infrastructure supplémentaire. C'est un template de prompting, applicable immédiatement, disponible en open access. Le surcoût est en tokens d'inference. Le gain potentiel : réduire ou éliminer les sandbox d'exécution dans les pipelines RL de coding agents.
- Les gains sont model-dépendants (forts avec Opus 4.5, plats avec Sonnet 4.5). Les modes d'erreur résiduels — indirection, défauts multi-fichiers, connaissance algorithmique manquante — sont les mêmes que ceux qui posent problème aux développeurs seniors. À 93 %, la technique est un complément aux outils d'analyse statique, pas encore un remplacement.
Questions fréquentes
Peut-on utiliser cette technique aujourd'hui en production?
Oui, sous conditions. Les templates sont disponibles, la technique est model-agnostique (elle fonctionne avec tout LLM suffisamment capable), et elle ne nécessite aucune infrastructure supplémentaire. La limite : le surcoût en tokens à l'inference et la dépendance au modèle — les gains sont significatifs avec les modèles de raisonnement avancé (Opus 4.5) mais marginaux avec les modèles plus légers.
Est-ce que ça remplace les outils d'analyse statique (SonarQube, Semgrep, CodeQL)?
Pas encore. Les outils d'analyse statique offrent des garanties formelles que le raisonnement semi-formel ne fournit pas. Mais la technique généralise à travers les langages et les frameworks là où chaque outil statique est spécifique. À 93 % de précision, c'est un complément solide pour les tâches où aucun outil statique n'existe ou où le contexte multi-langage rend les outils traditionnels inopérants.
Quel est l'impact sur le coût des pipelines d'entraînement d'agents de coding?
Potentiellement important. Les sandbox d'exécution utilisés pour vérifier les patchs dans les pipelines RL sont coûteux en compute et lents à scaler. Si la vérification sans exécution atteint 93 %, une partie du pipeline peut basculer vers le raisonnement semi-formel, réduisant le besoin de sandbox. Les chercheurs présentent explicitement la technique comme un « execution-free RL reward signal » viable.