Les modèles Gemini ne connaissaient pas leur propre API. Google a dû construire un MCP pour corriger le problème.
Les agents de coding sont entraînés sur des données qui ont une date de coupure. Quand un développeur demande à un agent de construire une application avec l'API Gemini, l'agent génère du code qui utilise des SDK anciens, des modèles dépréciés, et des patterns qui ne correspondent plus aux recommandations actuelles. Le résultat : du code qui compile peut-être, mais qui ne suit pas les bonnes pratiques, utilise des endpoints obsolètes, ou référence des fonctions qui n'existent plus dans la version courante.
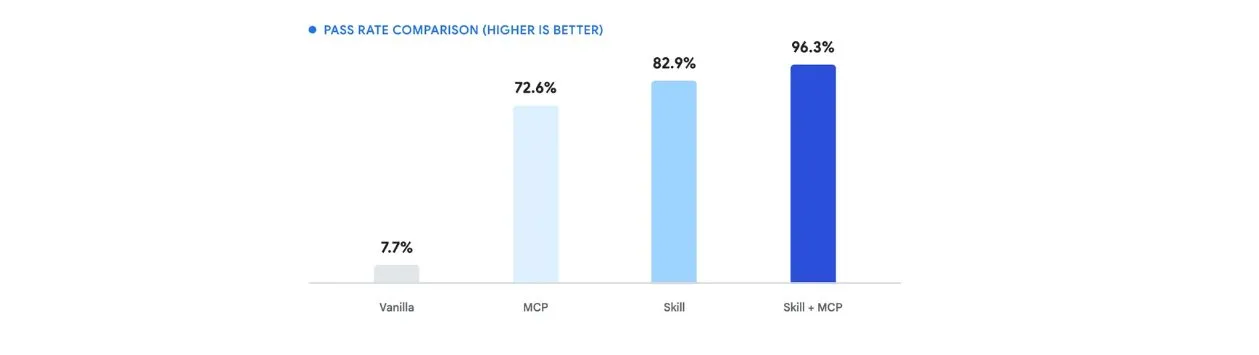
Google a mesuré l'ampleur du problème. Sur un jeu d'évaluation de 117 prompts couvrant des tâches de coding Python et TypeScript avec les SDK Gemini — agents, chatbots, traitement de documents, streaming, fonctionnalités SDK spécifiques — les modèles Gemini 3.0 Pro et Flash atteignent un taux de réussite de 6,8 % en mode vanilla. Gemini 3.1 Pro Preview monte à 28,2 %. Un prompt est considéré comme un échec s'il utilise l'un des anciens SDK de Google.
6,8 %. Le propre modèle de Google ne sait pas utiliser la propre API de Google.
Deux outils
Le Gemini API Docs MCP est un serveur MCP public hébergé à gemini-api-docs-mcp.dev. Il expose une fonction search_documentation que l'agent peut appeler pour récupérer en temps réel les définitions d'API, les patterns d'intégration et les exemples de code depuis la documentation officielle Gemini. Le serveur s'installe en une commande dans le terminal du projet.
Les Gemini API Developer Skills sont des fichiers d'instructions structurées — des « compétences » d'agent — qui injectent dans le contexte de l'agent les bonnes pratiques, les versions SDK courantes, les modèles recommandés, et les liens vers les ressources. Les skills fonctionnent en tandem avec le MCP : si le MCP est installé, le skill l'utilise pour la documentation. Si le MCP n'est pas installé, le skill récupère un fichier llms.txt depuis ai.google.dev comme fallback.
Les skills utilisent un mécanisme de « progressive disclosure » : seules les métadonnées (nom et description) sont chargées initialement. Les instructions détaillées et les ressources ne sont exposées que lorsque le modèle active explicitement la compétence, économisant des tokens de contexte.
Les résultats

Le gain combiné MCP + Skill est de 96,3 % avec 63 % de tokens en moins par réponse correcte. Le skill seul pousse Gemini 3.1 Pro de 28,2 % à 96,6 %. Gemini 3.0 Pro passe de 6,8 % à environ 87 %. Les modèles 2.5, plus anciens, voient des améliorations faibles — Google l'attribue à des capacités de raisonnement plus limitées.
Le chiffre de 63 % de réduction de tokens par réponse correcte est aussi important que le taux de réussite. Moins de tokens signifie un coût d'inference plus bas et une latence réduite. Le skill évite à l'agent de tâtonner vers la bonne réponse — il arrive plus directement au résultat parce qu'il dispose des patterns corrects dès le départ.
Le vrai sujet
Google vient d'admettre publiquement que ses propres modèles échouent à 93 % quand on leur demande d'utiliser sa propre API. Ce n'est pas un problème Gemini. C'est un problème structurel de tous les LLM : les données d'entraînement sont figées, les API évoluent, et l'écart se creuse à chaque mise à jour. OpenAI, Anthropic, Mistral, Meta — tous les fournisseurs de SDK ont le même problème. Chaque version d'API publiée après le cutoff d'entraînement est invisible pour l'agent.
La solution de Google est la première réponse documentée et mesurée à ce problème. L'architecture est modeste — un serveur MCP qui sert de la documentation et des fichiers d'instructions structurées — mais l'impact est disproportionné parce qu'elle s'attaque à la cause racine plutôt qu'au symptôme.
Les chercheurs de Google notent eux-mêmes que l'approche « structured agentic reasoning may offer a flexible alternative to classical static analysis tools » — une formulation qui résonne avec la technique de semi-formal reasoning publiée la même semaine par Meta. Les deux approches convergent sur la même idée : structurer ce que l'agent sait et comment il raisonne produit des gains massifs sans toucher aux poids du modèle.
AGENTS.md
Google mentionne une étude de Vercel qui suggère que donner des instructions directes aux modèles via un fichier AGENTS.md pourrait être encore plus efficace que les skills. C'est un aveu intéressant : le mécanisme le plus simple — un fichier markdown de bonnes pratiques dans le répertoire du projet — pourrait battre l'infrastructure MCP + Skills dans certains cas. Google explore les deux approches en parallèle.
Le concept de skills a été introduit fin 2025 par Anthropic et rapidement adopté par d'autres. L'écosystème est encore jeune. Le problème principal : il n'y a pas de mécanisme de mise à jour élégant. Les skills installés dans un workspace restent à leur version initiale sauf mise à jour manuelle. À terme, des skills obsolètes dans les workspaces pourraient « faire plus de mal que de bien », selon les propres termes de Google.
Pour n'importe quel SDK
L'approche est généralisable. N'importe quel mainteneur de SDK peut construire un serveur MCP qui sert sa documentation et des fichiers de skills qui injectent ses bonnes pratiques dans les agents de coding. L'infrastructure est open source. Les skills Gemini sont sur GitHub. Le format est un fichier d'instructions structuré que n'importe quel agent compatible peut consommer.
Pour un DSI qui gère des équipes de développement qui utilisent des agents de coding pour construire sur plusieurs API : le message est que chaque SDK non équipé de skills ou de MCP documentation va produire du code obsolète par défaut. L'audit des dépendances ne suffit plus — il faut auditer les connaissances de l'agent sur chaque API qu'il utilise.
Le serveur MCP Gemini expose une fonction search_documentation. Pas generate_code. Pas fix_code. Chercher de la documentation. L'agent fait le reste. La complexité architecturale est minimale. L'impact mesuré est un passage de 6,8 % à 96,3 %. Le ratio effort/résultat est difficile à ignorer.
TL;DR
Les modèles Gemini échouaient à 93 % sur leur propre API. Un serveur MCP + des fichiers d'instructions corrigent le problème et atteignent 96,3 % de réussite avec 63 % de tokens en moins. La solution est open source et applicable à n'importe quel SDK.
- Google publie le Gemini API Docs MCP (serveur de documentation en temps réel via Model Context Protocol) et les Agent Skills (instructions structurées de bonnes pratiques SDK). Combinés, ils font passer le taux de réussite sur 117 tâches de coding Gemini de 6,8 % (vanilla) à 96,3 %, avec 63 % de tokens en moins par réponse correcte.
- Le problème est structurel et touche tous les LLM : les données d'entraînement ont une date de coupure, les API évoluent, l'écart se creuse. La solution de Google est la première réponse documentée et mesurée — un serveur MCP qui sert de la documentation et des fichiers d'instructions qui injectent les patterns SDK corrects dans le contexte de l'agent.
- L'approche est généralisable : n'importe quel mainteneur de SDK peut construire le même type d'outillage. Pour les DSI, le message est que chaque API non équipée de skills va produire du code obsolète par défaut via les agents de coding. L'audit des connaissances de l'agent devient aussi important que l'audit des dépendances.
Questions fréquentes
Cela fonctionne-t-il avec des agents de coding non-Google (Claude Code, Cursor, Copilot)?
Le serveur MCP est compatible avec tout agent qui supporte le Model Context Protocol — ce qui inclut Claude Code, Cursor, et d'autres outils compatibles MCP. Les skills utilisent un format d'instructions structurées (skills.sh, Context7) qui est en voie de standardisation. Le bénéfice est maximal avec les modèles Gemini 3.x (qui ont la capacité de raisonnement pour exploiter les instructions), mais l'architecture est model-agnostique.
Pourquoi les anciens modèles Gemini (2.5) bénéficient-ils peu de ces outils?
Google l'attribue à des capacités de raisonnement plus limitées. Le skill fournit des instructions et des patterns, mais le modèle doit être capable de les interpréter, de les appliquer au contexte, et de les combiner avec les informations récupérées via le MCP. Les modèles plus récents (3.0, 3.1) ont cette capacité. Les plus anciens devinent plutôt que raisonnent — le skill ne compense pas ce déficit.
Est-ce que chaque fournisseur d'API devra construire son propre MCP et ses propres skills?
C'est la direction logique. Google a ouvert la voie avec Gemini, mais Stripe, Twilio, AWS, et tout SDK qui évolue plus vite que les cycles d'entraînement des LLM ont le même problème. L'alternative est d'attendre que les fournisseurs de modèles mettent à jour leurs données d'entraînement — ce qui est lent, coûteux, et ne résout pas le problème pour les versions intermédiaires.